OCI AI Ops framework for Cloud Operation Autonomous Resilience
OCI AI Ops framework for Cloud Operation Autonomous Resilience
In the legacy operations model, a pager sounds, a human engineer joins a bridge, and the first critical minutes are spent collecting context. Which system changed? Which database slowed down? Which application tier is producing errors? Which metric crossed a threshold? Which log message matters? Which business process is impacted? That model worked when environments were smaller, changes were slower, and operational knowledge could fit inside a few expert teams. It becomes fragile in a cloud operating model where applications are distributed, infrastructure is elastic, data platforms are mission critical, and signals arrive from many layers at the same time.
DevOps changed the industry by connecting development and operations: if you build it, you run it. But AI transformation is changing the operating model again. AI agents can now assist with code generation, application development, testing, and release engineering. The next logical step is AI Ops: using AI to operate the application, the infrastructure, the database estate, and the cloud platform itself.
The goal is not to remove people from operations. The goal is to move human experts out of repetitive correlation work and into architecture, governance, exception handling, and business decision-making. Autonomous resilience is the target state: systems that can sense, diagnose, plan, remediate, verify, and learn with appropriate human supervision.
What AI Ops means
AI Ops is the application of AI, automation, observability, and operational governance to run modern digital systems more intelligently. It is not just a chatbot attached to monitoring data. It is not a folder of scripts triggered by alerts. It is an architecture where telemetry, policies, agents, evaluators, workflows, and incident processes work together.
In a mature AI Ops model, the system can:
- Detect a performance, availability, capacity, security, or data-platform anomaly.
- Correlate signals across metrics, logs, events, traces, SQL data, and configuration context.
- Determine whether the event is noise, a real incident, a capacity risk, or an emerging business-impacting condition.
- Generate a remediation plan that explains both the technical action and the expected outcome.
- Validate the plan before execution through an evaluator or policy guardrail.
- Execute the approved remediation through controlled OCI services and APIs.
- Verify the post-execution result against the desired state.
- Produce an incident summary, problem record, and root cause analysis for future learning.
The key shift is that operations becomes an agentic loop, not a manual search exercise.
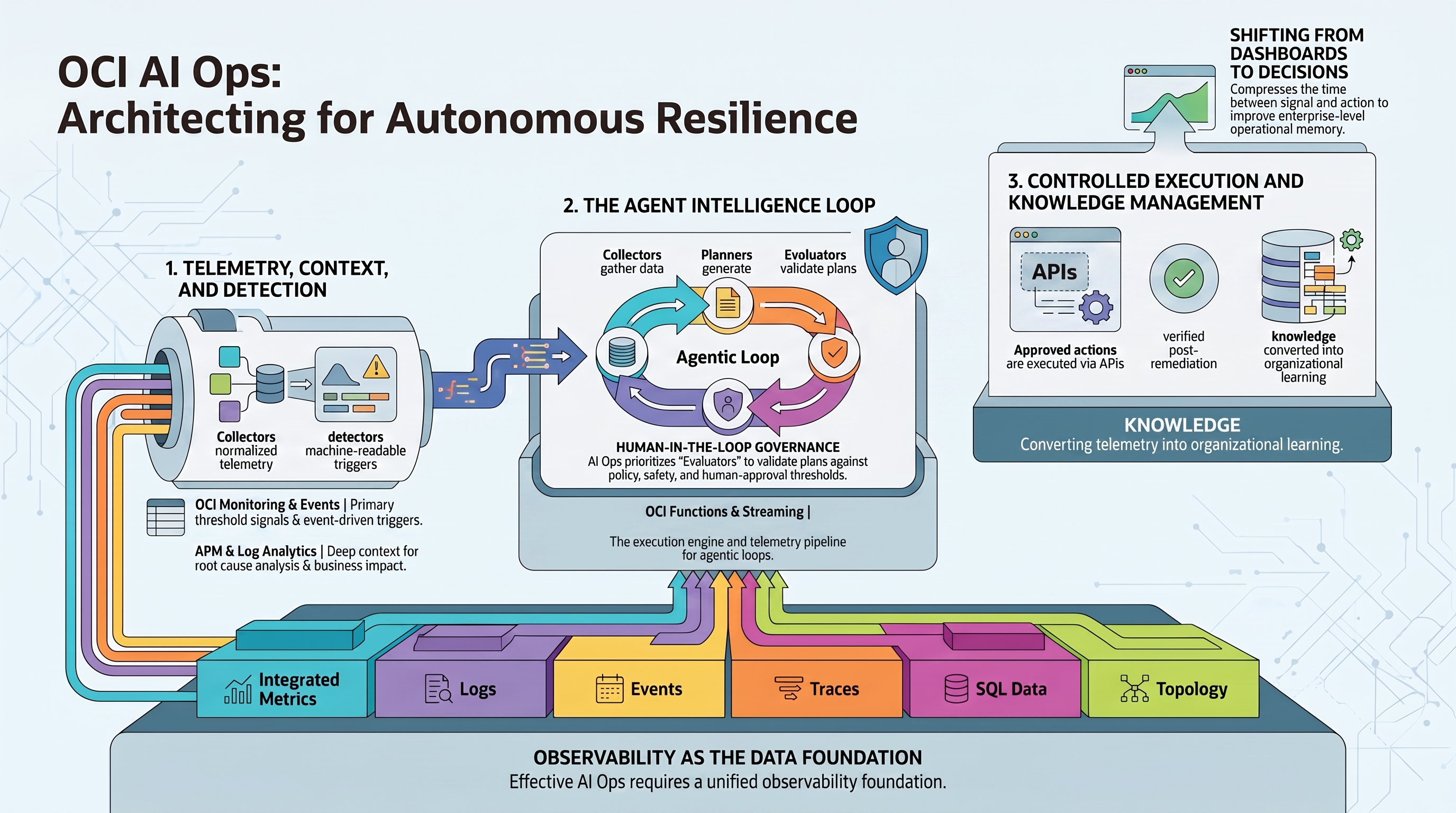
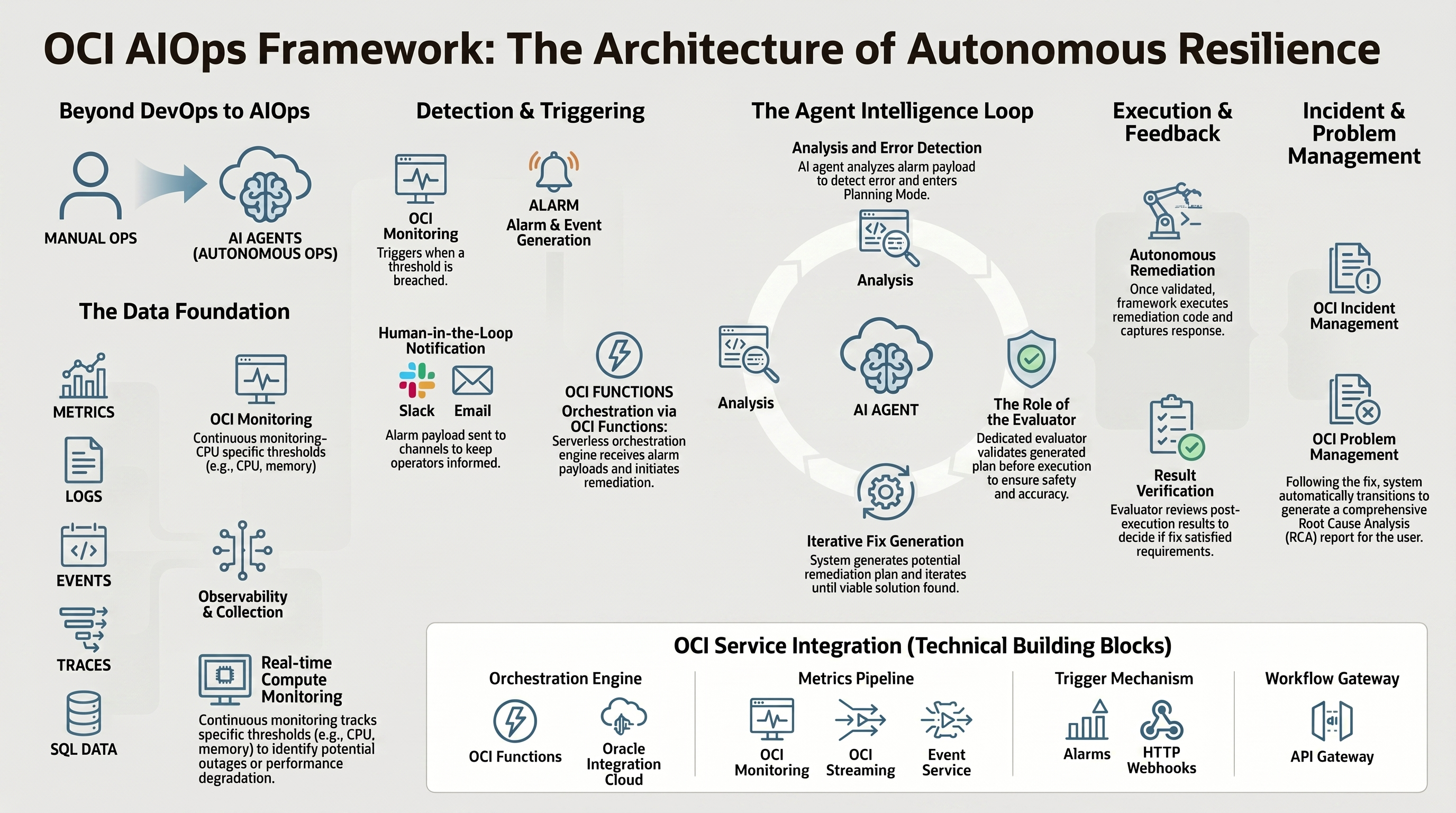 Figure 1: OCI AI Ops framework for autonomous resilience, from observability data foundation to agentic remediation and problem management.
Figure 1: OCI AI Ops framework for autonomous resilience, from observability data foundation to agentic remediation and problem management.
Observability is the data foundation
AI Ops begins with observability. An agent cannot diagnose what it cannot perceive. A framework that only sees CPU utilization cannot understand user experience. A framework that only sees logs cannot understand capacity. A framework that ignores database state cannot make reliable decisions for enterprise workloads.
The data foundation must include several classes of operational evidence:
- Metrics: numerical time-series data such as CPU, memory, storage, latency, queue depth, throughput, and error rate.
- Logs: detailed records from applications, infrastructure, databases, middleware, security systems, and integration platforms.
- Events: discrete changes in cloud resources, lifecycle state, configuration, alarms, and operational activity.
- Traces: end-to-end transaction paths across applications, APIs, services, and dependencies.
- SQL data: database-level state, workload, waits, sessions, execution patterns, backup posture, capacity, and performance signals.
- Topology and resource context: relationships across applications, compute, databases, networks, storage, tags, compartments, and business services.
For enterprise customers, this foundation is not only about troubleshooting. It is how the business understands operational risk, service performance, cost exposure, capacity pressure, and resilience posture.
OCI Observability and Management as the AI Ops service fabric
OCI provides a strong set of Observability and Management services that can become the service fabric for an AI Ops framework. Each service contributes a different kind of operational signal or control point.
| OCI capability | Role in the AI Ops framework |
|---|---|
| OCI Monitoring | Captures infrastructure and service metrics, evaluates alarms, and provides the primary threshold and anomaly signal for many operational workflows. |
| OCI Logging and Log Analytics | Centralizes logs, enriches and parses operational records, supports pattern detection, and provides the evidence base for root cause analysis. |
| Application Performance Monitoring | Captures traces, spans, user experience, service dependencies, and application latency so the agent can reason about business transaction impact. |
| Database Management Service | Provides database health, performance, fleet management, SQL diagnostics, sessions, wait events, and operational actions for database-centric workloads. |
| Operations Insights | Supports capacity planning, resource utilization analysis, SQL insights, database performance trends, and long-horizon operational forecasting. |
| Resource Analytics | Helps customers understand resource inventory, utilization, allocation, and optimization opportunities across cloud estates. |
| OCI Events Service | Detects resource changes and state transitions, then routes event-driven workflows to downstream automation. |
| OCI Streaming | Provides a scalable event and telemetry pipeline for decoupling producers, agent processors, and downstream consumers. |
| OCI Functions | Runs serverless detection, enrichment, planning, evaluation, remediation, and verification logic. |
| API Gateway and Oracle Integration Cloud | Exposes and orchestrates controlled workflow entry points, integrates with enterprise systems, and coordinates multi-step processes. |
When these services are connected into an architecture, they do more than generate dashboards. They create an operational decision fabric. Customers can use that fabric to understand which systems are at risk, which capacity trends require investment, which incidents have the highest business impact, and which remediations can be safely automated.
From dashboards to decisions
Traditional observability often stops at visibility. A dashboard shows that CPU is high, a database wait event is increasing, a transaction is slower than normal, or a log pattern is repeating. That visibility is useful, but it still leaves the human operator responsible for correlation, prioritization, and action.
AI Ops should move customers from dashboards to decisions.
For example:
- OCI Monitoring identifies a compute CPU saturation pattern.
- APM shows that the affected compute instance is part of a customer-facing application path.
- Log Analytics detects a repeating application error after a deployment.
- Database Management shows increased database sessions and wait events.
- Operations Insights indicates the workload has been trending toward a capacity ceiling for several weeks.
- Resource Analytics shows whether similar resources are underused elsewhere or whether the issue reflects a broader estate-level allocation pattern.
Individually, these are signals. Together, they tell a business story: which service is affected, why it matters, whether this is an incident or a capacity trend, what remediation is available, and which investment decision should be made next.
That is where AI Ops creates business value. It compresses the time between signal, understanding, action, and learning.
OCI reference architecture for autonomous resilience
The OCI AI Ops framework can be organized into five architectural layers.
1. Telemetry and context collection
The collector layer gathers operational evidence from OCI Monitoring, Logging, Log Analytics, Application Performance Monitoring, Database Management, Operations Insights, Resource Analytics, Events, traces, SQL diagnostics, and resource metadata.
This layer should normalize identity and context as much as possible. Resource OCIDs, compartment names, tags, application names, database names, service tiers, environment labels, and business ownership all matter. Without this context, an agent may understand the symptom but miss the business priority.
2. Detection and triggering
The detector layer turns telemetry into operational signals. OCI Monitoring alarms, OCI Events rules, Log Analytics patterns, APM thresholds, database performance indicators, capacity forecasts, and security anomalies can all become triggers.
In a traditional model, the trigger may send an email or open a ticket. In an AI Ops model, the trigger should also route the payload to the agentic workflow. The alarm still keeps humans informed, but the architecture redirects machine-readable context toward the system that can analyze and act.
The preferred pattern is:
OCI Monitoring / Events / Log Analytics / APM / Database signals -> OCI Streaming or Events -> OCI Functions -> Agent workflow
Slack, email, service desk, or collaboration notifications remain important, but they are supervisory channels. The operational payload should flow into the autonomous resilience framework.
3. Agent intelligence loop
The agent intelligence loop is the core of the architecture. It turns an alarm into an operational decision.
The loop includes several roles:
- Collector: gathers and enriches evidence from multiple OCI services.
- Detector: classifies the issue, such as performance degradation, outage, capacity pressure, database contention, security anomaly, or configuration drift.
- Planner: generates one or more remediation options and explains expected impact.
- Evaluator: validates the plan before execution against policy, safety, risk, and confidence thresholds.
- Orchestrator: coordinates the workflow across OCI Functions, API Gateway, Oracle Integration Cloud, service APIs, and downstream enterprise systems.
The evaluator is the most important governance component. A good AI Ops system should not simply generate a plan and execute it. It should ask whether the plan is safe, whether the evidence supports the action, whether the blast radius is acceptable, whether a human approval is required, and whether the proposed change aligns with operational policy.
4. Controlled execution and verification
Once the evaluator approves a remediation plan, the execution layer performs the action through a controlled service boundary. In OCI, this may involve OCI Functions, Resource Manager, Database Management operations, Compute APIs, autoscaling actions, integration workflows, or runbook automation.
The framework should capture every action as evidence:
- What plan was approved?
- Which policy or evaluator approved it?
- Which OCI identity executed the action?
- What resource changed?
- What was the expected outcome?
- What telemetry changed after execution?
Post-execution verification is mandatory. The evaluator should review metrics, logs, traces, database state, and application behavior after the remediation. If the system is not back within the desired state, the loop can generate another plan, escalate to a human operator, or open a problem-management workflow.
5. Incident, problem, and knowledge management
The agent’s responsibility does not end with remediation. The final layer turns an operational event into organizational learning.
After an incident, the framework should generate:
- An incident summary with timeline, affected systems, detected symptoms, and business impact.
- A root cause analysis that connects evidence from metrics, logs, traces, SQL data, and events.
- A remediation record describing what was proposed, what was approved, what was executed, and what changed.
- A problem-management recommendation if the issue reflects a recurring defect, capacity trend, design weakness, or process gap.
- A knowledge-base article or operational learning artifact that future agents and human operators can reuse.
This is how AI Ops becomes more than automation. Every event improves the operational memory of the enterprise.
Example: compute and database pressure
Consider a customer-facing application running on OCI Compute with an Oracle Database backend. OCI Monitoring detects that CPU utilization on the compute tier has crossed a threshold. Around the same time, Database Management shows increased sessions and wait events, APM shows higher transaction latency, and Log Analytics detects repeated timeout messages from the application.
In a traditional operations model, each signal may appear in a different console or dashboard. A human engineer has to assemble the timeline.
In the AI Ops framework, the alarm payload is routed to OCI Functions or OCI Streaming. The collector pulls related evidence from OCI Monitoring, APM, Log Analytics, Database Management, Operations Insights, and Resource Analytics. The detector classifies the condition as a possible application saturation and database response-time incident. The planner proposes remediation options such as scaling compute capacity, restarting a failed application component, tuning a database resource consumer group, or escalating because the confidence is too low for autonomous execution.
The evaluator checks the plan. If the action is low risk and policy-approved, the orchestrator executes it. If the action affects production capacity, database configuration, or business-critical workloads, the framework may require human approval through Slack, email, service desk, or an approval workflow.
After execution, the evaluator verifies whether CPU, latency, database waits, application errors, and transaction success rate returned to expected ranges. The framework then generates an incident summary and RCA, including the evidence chain that led to the remediation.
Human in the loop is a design principle
Autonomous resilience does not mean unsupervised change. The architecture should distinguish between informational actions, low-risk remediation, high-risk remediation, and business-impacting change.
Some actions can be fully autonomous, such as collecting additional diagnostics, enriching an incident, correlating logs, or creating an RCA draft. Some actions may be conditionally autonomous, such as restarting a stateless component or scaling a pool within an approved limit. Other actions should require explicit approval, such as changing database configuration, modifying network policy, altering security controls, or executing a remediation with uncertain blast radius.
The human-in-the-loop model should be built into the architecture from the beginning. Notifications are not only for awareness. They are a governance mechanism that keeps experts informed, captures approvals, and maintains trust.
Why this matters for customers
Customers do not adopt AI Ops because they want a new dashboard. They adopt it because cloud complexity is creating operational risk and slowing business decisions.
An OCI AI Ops framework can help customers answer higher-value questions:
- Which systems are most likely to fail or breach performance targets?
- Which applications are consuming more capacity than their business value justifies?
- Which database workloads need tuning, scaling, or architectural change?
- Which incidents are recurring because the root problem was never removed?
- Which operational risks are isolated, and which indicate a systemic pattern?
- Which remediation actions are safe enough to automate, and which still need expert approval?
- Which infrastructure and application investments will improve resilience the most?
This is where OCI Observability and Management services become strategic. OCI Monitoring, Log Analytics, Database Management, Operations Insights, APM, Resource Analytics, Events, Streaming, and Functions provide the operational evidence and workflow backbone. AI agents provide the reasoning, planning, and summarization layer. Evaluators provide safety. Human experts provide judgment and accountability.
Conclusion
AI Ops is not a replacement for DevOps. It is the next evolution of cloud operations. DevOps connected builders and operators. AI Ops connects observability, automation, AI agents, governance, and business decision-making into one operating model.
For OCI customers, the opportunity is significant. The same services already used for monitoring, logging, application performance, database management, capacity planning, event routing, and serverless automation can become the foundation of an autonomous resilience framework.
The future of cloud operations will not be defined by how many alerts a team can process. It will be defined by how quickly the organization can convert telemetry into understanding, understanding into safe action, and action into durable operational knowledge.
Authors
- Royce Fu is a Master Principal Cloud Architect at Oracle on the Observability and Management Specialist team. His work focuses on OCI observability, AIOps, Oracle Database, and enterprise-scale operational intelligence.
- Adrian Birzu is Observability and Security Domain Blackbelt at Oracle EMEA CTO Office. Adrian has around 18 years of work experience, and his focus is on OCI, Observability, Multicloud and Security and provide solutions to our customers challenges.